The C++ programming languages were designed as general-purpose languages for systems running within a single address space on one computer. Although you can use these languages to develop distributed systems by adding networking libraries such as Windows Sockets, the languages themselves have no special features in this regard. As a result, passing parameters to a function is as simple as pushing them onto the stack, jumping to the function address, and then popping the parameters off the stack. With the exception of the function's return value, parameters need not be passed back to the caller when the function returns because C++ specifies that parameters are passed by value. This means that a copy of the values is passed to a function, and any changes made to those values within the function are not reflected back to the caller when the function returns. The following code fragment illustrates this situation:
void sum(int x, int y, int sum)
{
sum = x + y
}
void main()
{
int result = 0;
sum(5, 3, result);
printf("5 + 3 = %d\n", result); // Prints 0
}
|
Pass-by-value semantics in C++ can be contrasted with languages such as Visual Basic and Fortran, which, by default, pass parameters by reference, as shown in the following Visual Basic code:2
Sub Sum(X As Integer, Y As Integer, Sum As Integer) Sum = X + Y End Sub Sub Form_Load() Dim Result As Integer Sum 5, 3, Result Print "5 + 3 = " & Result ' Prints 8 End Sub |
Of course, in C++ you can achieve pass-by-reference functionality using pointers or references. When you use pointers, the address of the variable is passed to the function, causing any changes to the memory pointed to by the pointer to be immediately visible to the caller, as shown in the following code:
void sum(int x, int y, int* sum)
{
*sum = x + y
}
void main()
{
int result = 0;
sum(5, 3, &result);
printf("5 + 3 = %d\n", result); // Prints 8
}
|
When you pass parameters by value to a remote function, the system sends the value of the variable across the network to the server. However, several problems arise when you use pointers to pass data to code in another address space. The most obvious problem is that passing the address of a variable in one address space to a function in another address space does not work. To overcome this situation, the system must send the data that is stored at the location specified by the pointer across the network to the server. Memory is allocated to store the value in the address space of the server process, and then the address of the newly allocated memory is passed to the function. All this must be done as transparently as possible.
One of the problems with passing pointers is that C++ syntax does not indicate whether the function actually modifies the data that a specific function argument points to. For example, a pointer to some data might be passed to a function that uses that data in a read-only manner. In other cases, such as the sum function in the preceding code, a pointer is passed to a function for the sole purpose of retrieving data when the function returns. In a third variation on the same theme, a function might both read and write data that is passed via a pointer. The C++ syntax does not express these variations because it assumes that the caller and the function are both running in the same address space. Note that you can use the const keyword to indicate that a function does not modify data through a pointer.
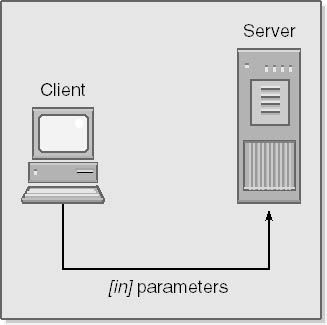
For calls between machines, however, this situation is not merely syntactical hairsplitting. The system must pass the data located at the address specified by any pointer parameters to the server when the call is made and then back to the client when the function returns. Since IDL was designed to facilitate the development of distributed systems, one of its goals is to reduce the amount of network traffic generated by remote calls. For this reason, IDL offers three directional attributes to standard C++-style syntax: [in], [out], and [in, out]. If no attribute is specified, by default parameters are passed to the server as part of the request message used to invoke a method, as shown in the following illustration.
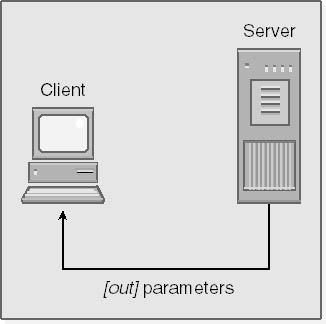
The [out] attribute indicates that data must be sent back to the client in the response message when the function call completes. This attribute is meaningful only when applied to a pointer argument because, by default, function parameters in C++ are passed by value. When the call returns, the system allocates memory in the client's address space to store the data returned; the caller is responsible for freeing this memory. The [out] attribute is a good choice when a pointer is passed to a function solely to retrieve data, as in the sum function shown previously. The process of passing a parameter with the [out] attribute is illustrated below.
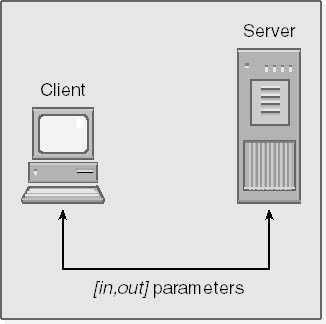
The [in, out] attribute indicates that the data at the location specified by a pointer parameter must be passed to the server as part of the request message and then back to the client in the response message. On the server side, the function frees and then reallocates a new buffer, if necessary. On the client side, the system copies the new data returned by the function over the original data, and the client ultimately frees this memory. This technique is used when a function expects to receive meaningful data and the caller expects it to return meaningful data to the same memory address. Since the [in, out] attribute transparently models the way normal C++ code works at the expense of extra network traffic, you should use it only when necessary. The action of a parameter with the [in, out] attribute is illustrated below.