The IDispatch interface was defined so that a single, standard interface2 could be used by all components wanting to expose their functionality to interested clients. This interface, and the marshaling code built for it, are now known as the Automation facility. You might wonder how a single interface can expose the functionality of any application. After all, how could the designers of IDispatch imagine every possible object, property, method, and event that an application might want to expose? The IDispatch interface would have to contain an infinite number of methods. In fact, the genius of IDispatch is that it was defined using just four methods—GetTypeInfoCount, GetTypeInfo, GetIDsOfNames, and Invoke. Here is the IDispatch interface defined in Interface Definition Language (IDL) notation:
interface IDispatch : IUnknown
{
// Do you support type information?
HRESULT GetTypeInfoCount(
[out] UINT* pctinfo);
// Gimme a pointer to your object's type information.
HRESULT GetTypeInfo(
[in] UINT iTInfo,
[in] LCID lcid,
[out] ITypeInfo** ppTInfo);
// Gimme a DISPID of a method or parameters.
HRESULT GetIDsOfNames(
[in] REFIID riid,
[in, size_is(cNames)] LPOLESTR* rgszNames,
[in] UINT cNames,
[in] LCID lcid,
[out, size_is(cNames)] DISPID* rgDispId);
// Call that method.
HRESULT Invoke(
[in] DISPID dispIdMember,
[in] REFIID riid,
[in] LCID lcid,
[in] WORD wFlags,
[in, out] DISPPARAMS* pDispParams,
[out] VARIANT* pVarResult,
[out] EXCEPINFO* pExcepInfo,
[out] UINT* puArgErr);
};
|
To better understand how the IDispatch interface works, it is helpful to think of it as a kind of surrogate interface. IDispatch doesn't offer any functionality of its own; it acts only as a standard conduit between a client and a component's functionality. The central IDispatch method is IDispatch::Invoke, which a client calls to invoke a particular method in the component. A unique number, called a dispatch identifier (DISPID), identifies each method. The Invoke method also takes a pointer to a DISPPARAMS structure containing the actual parameters to be passed to the method being called. Because the IDispatch marshaler knows how to marshal a pointer to the DISPPARAMS structure, it can marshal any Automation-based interface.
While IDispatch is not our favorite interface, we love the marshaler that Microsoft wrote for it. Usually called the type library marshaler because it performs marshaling based on the contents of a type library, this marshaler (contained in oleaut32.dll) can be used not only for IDispatch-based interfaces but also for custom interfaces that restrict themselves to Automation-compatible types.
To use the type library marshaler, you include the oleautomation attribute in the IDL file.3 When you call RegisterTypeLib or LoadTypeLibEx to register a type library, the function checks the type library for the oleautomation attribute. If the flag is present, the ProxyStubClsid32 key in the registry is automatically set to point to the type library marshaler. This feature saves you from always having to build and register a proxy/stub DLL for any custom interfaces. Of course, because the Automation marshaler is general, it cannot match the performance of a standard proxy/stub DLL built from the code generated by Microsoft IDL (MIDL). Nevertheless, in many situations the advantages of not having to build and register a proxy/stub DLL might outweigh the slight loss in performance from using the type library marshaler. (For more information about marshaling, see Chapters 14 and 15.)
The Automation-compatible types are described in the following table along with the equivalent native types in C++, Visual Basic, and Java. Most of the types are relatively self-explanatory; several, such as variants, safe arrays, BSTRs, and user-defined types, require special treatment and are described in detail in the sections that follow.
| Automation-Compatible IDL Types | C++ | Visual Basic | Java |
|---|---|---|---|
| boolean | Bool | Boolean | boolean |
| double | Double | Double | double |
| float | Float | Single | float |
| signed int | int/long | Long | int |
| signed short | Short | Integer | short |
| enum | Enum | Enum | com.ms.wfc.core.Enum |
| BSTR | BSTR | String | java.lang.String |
| CYCY | CY | Currency | long |
| DATE | DATE | Date | double |
| IDispatch* | IDispatch* | Object | java.lang.Object |
| IUnknown* | IUnknown* | IUnknown | com.ms.com.IUnknown |
| SAFEARRAY | SAFEARRAY | [] (A standard Visual Basic array) | com.ms.com.SafeArray |
| VARIANT | VARIANT | Variant | com.ms.com.Variant |
All method parameters accessed via the IDispatch interface are dealt with as variants. A variant is defined by the VARIANT structure declared in the oaidl.idl system IDL file. The VARIANT structure, shown here, is basically a giant union of all Automation-compatible types. Variants can contain strings, scalars, object references, or arrays. Each variant contains a VARTYPE member (defined as an unsigned short in wtypes.idl file) named vt that indicates the type of data currently stored by the variant. This member should be set to the correct VT_ prefixed constant.4
struct tagVARIANT {
union {
struct __tagVariant {
VARTYPE vt;
WORD wReserved1;
WORD wReserved2;
WORD wReserved3;
union {
LONG lVal; // VT_I4
BYTE bVal; // VT_UI1
SHORT iVal; // VT_I2
FLOAT fltVal; // VT_R4
DOUBLE dblVal; // VT_R8
VARIANT_BOOL boolVal; // VT_BOOL
SCODE scode; // VT_ERROR
CY cyVal; // VT_CY
DATE date; // VT_DATE
BSTR bstrVal; // VT_BSTR
IUnknown *punkVal; // VT_UNKNOWN
IDispatch *pdispVal; // VT_DISPATCH
SAFEARRAY *parray; // VT_ARRAY
BYTE *pbVal; // VT_BYREF|VT_UI1
SHORT *piVal; // VT_BYREF|VT_I2
LONG *plVal; // VT_BYREF|VT_I4
FLOAT *pfltVal; // VT_BYREF|VT_R4
DOUBLE *pdblVal; // VT_BYREF|VT_R8
VARIANT_BOOL *pboolVal; // VT_BYREF|VT_BOOL
SCODE *pscode; // VT_BYREF|VT_ERROR
CY *pcyVal; // VT_BYREF|VT_CY
DATE *pdate; // VT_BYREF|VT_DATE
BSTR *pbstrVal; // VT_BYREF|VT_BSTR
IUnknown **ppunkVal; // VT_BYREF|VT_UNKNOWN
IDispatch **ppdispVal; // VT_BYREF|VT_DISPATCH
SAFEARRAY **pparray; // VT_BYREF|VT_ARRAY
VARIANT *pvarVal; // VT_BYREF|VT_VARIANT
PVOID byref; // VT_BYREF
CHAR cVal; // VT_I1
USHORT uiVal; // VT_UI2
ULONG ulVal; // VT_UI4
INT intVal; // VT_INT
UINT uintVal; // VT_UINT
DECIMAL *pdecVal; // VT_BYREF|VT_DECIMAL
CHAR *pcVal; // VT_BYREF|VT_I1
USHORT *puiVal; // VT_BYREF|VT_UI2
ULONG pulVal; // VT_BYREF|VT_UI4
INT *pintVal; // VT_BYREF|VT_INT
UINT *puintVal; // VT_BYREF|VT_UINT
struct __tagBRECORD {
PVOID pvRecord;
IRecordInfo* pRecInfo;
}; __VARIANT_NAME_4; // VT_RECORD
} __VARIANT_NAME_3;
} __VARIANT_NAME_2;
DECIMAL decVal;
} __VARIANT_NAME_1;
};
|
Several helper functions make working with the VARIANT type easier; these are described in the table below. You can manipulate the VARIANT structure directly in C++, but you should use the helper functions instead because doing so ensures uniformity across applications that deal with variants. The most important and error-prone aspect of working with variants is the type conversion and coercion rules. Although a method of an IDispatch-based interface can be defined as expecting a string parameter, a client might choose to provide a numeric value instead. The Visual Basic statement Form1.Caption = 123 illustrates this. Conversely, a client might pass a variant containing a string to a method expecting a floating-point value, as in the Visual Basic statement Form1.Left = "132.4".
| Function | Description |
|---|---|
| VariantChangeType(Ex) | Converts a variant from one type to another |
| VariantClear | Clears a variant |
| VariantCopy | Frees the destination variant and makes a copy of the source variant |
| VariantCopyInd | Frees the destination variant and makes a copy of the source variant, performing the necessary indirection if the source is specified to be VT_BYREF |
| VariantInit | Initializes a variant |
The VariantChangeType(Ex) function is the primary function used to convert variants from one type to another. Typically, the implementation of the IDispatch::Invoke method converts each variant parameter to the desiredtype using the VariantChangeType(Ex) function. If unsuccessful,VariantChangeType(Ex) returns the value DISP_E_TYPEMISMATCH; this error should be returned to the client application by the Invoke method. The code fragment below illustrates the use of the several variant helper functions, including VariantChangeType:
// Declare two variants. VARIANT v1; VARIANT v2; // Initialize both of them. VariantInit(&v1); VariantInit(&v2); // v1 = A long with the value of 5 v1.vt = VT_I4; v1.lVal = 5; // Convert v1 to a string and store the result in v2. HRESULT hr = VariantChangeType(&v2, &v1, 0, VT_BSTR); if(SUCCEEDED(hr)) wprintf(L"%s\n", v2.bstrVal); // Displays 5 // Free the string in v2. VariantClear(&v2); |
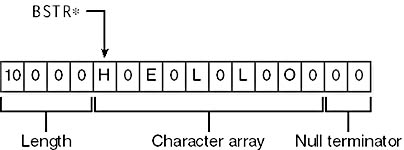
Most programming languages have their own notion of what a string is and how to store one in memory. C++ stores strings as an array of ASCII or Unicode characters with a null terminator; Visual Basic stores strings as an array of ASCII characters and prefixes the string with a value indicating its length; Java stores strings as an array of Unicode characters with a null terminator. All COM+ API functions that accept string arguments require null-terminated Unicode strings. To enable components built in different languages to exchange strings, Microsoft defined a new type of string: the BASIC string (BSTR). A BSTR is basically a length-prefixed, null-terminated array of Unicode characters. In C++, you can treat a BSTR and an array of OLECHARs almost identically. But because the BSTR is prefixed by its length, it might contain embedded null characters. Figure 5-1 shows the in-memory representation of a BSTR containing the string "Hello":
Figure 5-1. The memory layout of a BSTR.
Because of the support built into the Visual Basic and Java virtual machines, BSTRs automatically map onto the native string formats of these languages. C++ developers, however, must use special helper functions that deal with BSTRs, as described in the following table. The functions that create and delete BSTRs cache memory to improve the performance of those functions. For example, when a BSTR is freed, that memory is put into a cache. If the application later allocates another BSTR, it might get the free block from the cache. The code fragment below shows the use of several popular BSTR routines:
// Declare a BSTR. BSTR b1; // Allocate a new BSTR containing some text. b1 = SysAllocString(L"Testing BSTRs"); // Display the BSTR. wprintf(L"%s\n", b1); // Display the number of bytes (2 bytes per ANSI character). wprintf(L"%d bytes\n", SysStringByteLen(b1)); // Display the number of characters. wprintf(L"%d characters\n", SysStringLen(b1)); // Free the BSTR. SysFreeString(b1); |
| Function | Description |
|---|---|
| SysAllocString | Allocates a BSTR and copies a string into it |
| SysAllocStringByteLen | Takes an ANSI input string and returns a BSTR |
| SysAllocStringLen | Allocates a new BSTR, copies a specified number of characters into it, and then appends a null character |
| SysFreeString | Frees a BSTR |
| SysReAllocString | Allocates a new BSTR, copies the passed string into it, and then frees the old BSTR |
| SysReAllocStringLen | Creates a new BSTR containing a specified number of characters from an old BSTR, and then frees the old BSTR |
| SysStringByteLen | Returns the length (in bytes) of a BSTR |
| SysStringLen | Returns the length of a BSTR |
The SAFEARRAY type is important because it makes array manipulation safer in high-level languages such as Visual Basic. Unlike standard vectors in C++, a SAFEARRAY contains information about the number of dimensions and the current array bounds. You can also use safe arrays to pass arrays in variant parameters used by IDispatch-based interfaces. The array descriptor that defines a safe array type is shown in Figure 5-2.
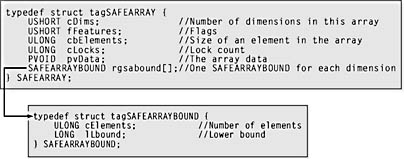
Figure 5-2. The SAFEARRAY and SAFEARRAYBOUND structures.
A safe array can store a multidimensional array of data. In standard C++ notation, such an array might be defined as long myArray[2][4]. If defined in a safe array, this type of array would have two dimensions (cDims). For each dimension in a SAFEARRAY, a corresponding SAFEARRAYBOUND structure, shown in Figure 5-3, is created and pointed to by the rgsabound member of the SAFEARRAY structure. Each SAFEARRAYBOUND defines the number of elements in that dimension and the starting index value of the dimension. In the sample array long myArray[2][4], two SAFEARRAYBOUND structures are created, each with four elements (cElements) and a lower bound of 0 (lLbound).
While safe arrays are exposed as natural language-based arrays in Visual Basic, C++ developers must once again deal with special structures and helper functions when working with safe arrays. The safe array helper functions shown in the table below create, manipulate, and delete safe arrays in C++. SafeArrayCreate(Ex) and SafeArrayDestroy are the most basic. SafeArrayCreateVector(Ex) differs from SafeArrayCreate(Ex) in that it can be used only to create one-dimensional arrays.
| Function | Description |
|---|---|
| SafeArrayAccessData | Increments the lock count of an array and returns a pointer to array data |
| SafeArrayAllocData | Allocates memory for a safe array based on a descriptor created with SafeArrayAllocDescriptor |
| SafeArrayAllocDescriptor(Ex) | Allocates memory for a safe array descriptor |
| SafeArrayCopy | Copies an existing array |
| SafeArrayCopyData | Copies a source array to a target array after releasing target resources |
| SafeArrayCreate(Ex) | Creates a new array descriptor |
| SafeArrayCreateVector(Ex) | Creates a one-dimensional array whose lower bound is always 0 |
| SafeArrayDestroy | Destroys an array descriptor |
| SafeArrayDestroyData | Frees memory used by the data elements in a safe array |
| SafeArrayDestroyDescriptor | Frees memory used by a safe array descriptor |
| SafeArrayGetDim | Returns the number of dimensions in an array |
| SafeArrayGetElement | Retrieves an element of an array |
| SafeArrayGetElemsize | Returns the size of an element |
| SafeArrayGetLBound | Retrieves the lower bound for a given dimension |
| SafeArrayGetUBound | Retrieves the upper bound for a given dimension |
| SafeArrayLock | Increments the lock count of an array |
| SafeArrayPtrOfIndex | Returns a pointer to an array element |
| SafeArrayPutElement | Assigns an element to an array |
| SafeArrayRedim | Resizes a safe array |
| SafeArrayUnaccessData | Frees a pointer to array data and decrements the lock count of the array |
| SafeArrayUnlock | Decrements the lock count of an array |
| SafeArraySetRecordInfo | Sets the RecordInfo stored in the given safe array |
| SafeArrayGetRecordInfo | Retrieves the RecordInfo of a safe array |
| SafeArraySetIID | Sets the GUID of the interface for the given safe array |
| SafeArrayGetIID | Returns the GUID of the interface for the given safe array |
| SafeArrayGetVartype | Returns the type stored in the given safe array |
The code fragment below creates a two-dimensional safe array, with each dimension holding four long values:
// Create a SAFEARRAY of this type: long myArray[2][4]; SAFEARRAYBOUND pSab[2]; pSab[0].lLbound = 0; pSab[0].cElements = 4; pSab[1].lLbound = 0; pSab[1].cElements = 4; SAFEARRAY* pSa; pSa = SafeArrayCreate(VT_I4, 2, pSab); if(pSa == NULL) cout << "SafeArrayCreate failed" << endl; |
You can use the SafeArrayGetElement and SafeArrayPutElement functions to read and write data in the array one value at a time. For example, the code fragment below assigns the value 3 to an element in the array using the SafeArrayPutElement function:
// long myArray[2][4];
// myArray[1][2] = 3; // leftmost dimension first (the standard way)
// 0 1 2 3
// |---|---|---|---|
// 0 | x | x | x | x |
// |---|---|---|---|
// 1 | x | x | 3 | x |
// |---|---|---|---|
long index[2] = { 2, 1 }; // rightmost dimension first
long data = 3;
SafeArrayPutElement(pSa, index, &data);
|
The tricky part of the SafeArrayPutElement function is figuring out how to identify the desired element in the safe array. The second parameter of SafeArrayPutElement is a pointer to a vector of indexes for each dimension of the array. The rightmost (least significant) dimension is placed first in the vector (index[0]); the leftmost dimension is stored last (index[pSa->cDims - 1]). This is worth noting because it is exactly the opposite of how multidimensional arrays are accessed in C++. You can think of a two-dimensional array as a spreadsheet-style grid pattern, as shown in the code fragment above.
The obvious limitation of the SafeArrayPutElement and SafeArrayGetElement functions is that they manipulate only one value at a time. This can hurt performance when you do extensive work with safe arrays. As an alternative, you can call the SafeArrayAccessData and SafeArrayUnaccessData functions. SafeArrayAccessData locks the array in memory and returns a pointer to the data held by the safe array. This enables direct access to the data in the safe array. In the code fragment below, SafeArrayAccessData is called to obtain the array data. Then all the elements in the array are set directly via the pointer, after which SafeArrayUnaccessData is called to unlock the array. The SafeArrayGetElement function is then called to retrieve one element from the array to verify that the direct pointer access was successful. Finally the safe array is freed by calling the SafeArrayDestroy function.
// Lock the array get a pointer to its data. long* pData; SafeArrayAccessData(pSa, (void**)&pData); // Set or get any values in the array. *pData = 4; *(pData + 1) = 5; *(pData + 2) = 6; *(pData + 3) = 7; *(pData + 4) = 8; *(pData + 5) = 9; *(pData + 6) = 10; *(pData + 7) = 11; // Unlock the array. (pData is no longer valid.) SafeArrayUnaccessData(pSa); // Now get one element by calling SafeArrayGetElement. index[0] = 3; index[1] = 1; SafeArrayGetElement(pSa, index, &NewData); cout << NewData << endl; // Displays 11 // When finished, free the array. SafeArrayDestroy(pSa); |
When storing a safe array in a variant, you simply OR the variant type (VARIANT.vt) element with the VT_ARRAY flag, as shown below:
VARIANT v3; VariantInit(&v3); v1.vt = VT_I4|VT_ARRAY; // Array of 4 byte integers v1.parray = pSa; |
In the past, data structures could be passed to methods of v-table based interfaces, but only if those interfaces were marshaled by a proxy/stub DLL generated by the MIDL compiler. Interfaces that relied on type library marshaling, such as interfaces defined in Visual Basic or Java, could not accept structures as method arguments because the type library marshaler was not capable of handling these complex types. Since that time, the type library marshaler has been extended to support user-defined types (UDTs) and arrays of UDTs if they are passed using a safe array. To employ a UDT as a method argument, you define the structure in an IDL file, which is then compiled with MIDL to produce the type library. A sample UDT defined in IDL is shown here; notice that the typedef IDL keyword is used to assign a GUID to the structure.
typedef [ uuid(10000099-0000-0000-0000-000000000001)]
struct myDataType {
int x;
int y;
} myDataType;
|
You can also pass UDTs as arguments to methods of a pure IDispatch interface using the variant type. A variant of the type VT_RECORD wraps a pointer to a RecordInfo object that contains the necessary information about the UDT. The system-provided RecordInfo object implements the IRecordInfo interface, as shown below in IDL notation:
interface IRecordInfo: IUnknown
{
HRESULT RecordInit([out] PVOID pvNew);
HRESULT RecordClear([in] PVOID pvExisting);
HRESULT RecordCopy([in] PVOID pvExisting, [out] PVOID pvNew);
HRESULT GetGuid([out] GUID* pguid);
HRESULT GetName([out] BSTR* pbstrName);
HRESULT GetSize([out] ULONG* pcbSize);
HRESULT GetTypeInfo([out] ITypeInfo** ppTypeInfo);
HRESULT GetField([in] PVOID pvData, [in] LPCOLESTR szFieldName,
[out] VARIANT* pvarField);
HRESULT GetFieldNoCopy([in] PVOID pvData, [in] LPCOLESTR szFieldName,
[out] VARIANT* pvarField, [out] PVOID* ppvDataCArray);
HRESULT PutField([in] ULONG wFlags, [in,out] PVOID pvData,
[in] LPCOLESTR szFieldName, [in] VARIANT* pvarField);
HRESULT PutFieldNoCopy([in] ULONG wFlags, [in,out] PVOID pvData,
[in] LPCOLESTR szFieldName, [in] VARIANT* pvarField);
HRESULT GetFieldNames([in,out] ULONG * pcNames,
[out,size_is(*pcNames),length_is(*pcNames)] BSTR* rgBstrNames);
BOOL IsMatchingType([in] IRecordInfo* pRecordInfo);
PVOID RecordCreate();
HRESULT RecordCreateCopy([in] PVOID pvSource, [out] PVOID* ppvDest);
HRESULT RecordDestroy([in] PVOID pvRecord);
}
|
The IRecordInfo interface enables UDTs to be passed using variant types for IDispatch-based interfaces. At run time, a pointer to the system implementation of the IRecordInfo interface is obtained via a call to the GetRecordInfoFromTypeInfo or GetRecordInfoFromGuids function. The GetRecordInfoFromTypeInfo function retrieves the RecordInfo object for the UDT described in your type information. The code fragment shown here loads the type library, gets the type information for the UDT, and then calls GetRecordInfoFromTypeInfo.
ITypeLib* pTypeLib = 0;
HRESULT hr = LoadTypeLibEx(L"component.exe", REGKIND_DEFAULT, &pTypeLib);
ITypeInfo* pTypeInfo = 0;
const GUID GUID_myDataType =
{0x10000099,0x0000,0x0000,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x01};
hr = pTypeLib->GetTypeInfoOfGuid(GUID_myDataType, &pTypeInfo);
pTypeLib->Release();
IRecordInfo* pRecordInfo = 0;
hr = GetRecordInfoFromTypeInfo(pTypeInfo, &pRecordInfo);
pTypeInfo->Release();
pRecordInfo->Release();
|