For as long as personal computers have existed, the industry has provided increasingly powerful hardware for CPU-hungry software. Companies such as Intel have upgraded their processors from 8 to 16 to 32 bits and have increased their clock speed from 4.77 to over 550 megahertz (MHz). Under development are 64-bit processors that will run at still higher clock speeds. Yet the cost of developing a new processor is so prohibitive that only the largest corporations can afford the expense of upgrading. And we might someday run into the law of diminishing returns, making the expense of development outweigh the possible improvements.
Many other ways have been suggested for improving overall processing speed. Foremost has been the concept of parallel processing. Parallel processing holds that in an ideal environment, if one CPU can do x amount of work in a certain amount of time, 10 CPUs can do 10x work in the same time. Parallel processing can be implemented in two major ways: symmetric multiprocessing (SMP) and distributed computing.
With SMP, several (or several hundred) CPUs are placed inside a single computer. The host operating system must support multithreading so that different threads can be scheduled to run on different CPUs concurrently. Implementing SMP requires special software support. Microsoft Windows NT, for example, was one of the first PC operating systems capable of supporting SMP. Today, Microsoft Windows 2000 can quite flexibly support up to 16 processors.
For our purposes, we will define distributed computing as a system in which computers are interconnected for the purpose of sharing CPU power and appear to users as a single application. The definition is rather vague when it comes to how the computers are interconnected. (According to this definition, sending a document to a remote color printer by copying the document from your computer to a floppy disk, walking to the computer connected to the color printer, inserting the disk, and printing the document qualifies as an example of distributed computing.) In theory, the exact manner in which computers are interconnected is irrelevant. Perhaps the more important issue is the throughput provided by the information conduit. A distributed system connected by a 100-megabits-per-second, Ethernet-based local area network (LAN) will yield very different performance from a system connected by a 56 Kbps modem.
Before expanding on our definition of distributed computing, let's explore a realistic, albeit hypothetical, distributed system. A large bank has branch offices all over the world. The bank used to have a mainframe-based computing center at its world headquarters, and all branch offices used terminals connected to that mainframe. All account and customer information was therefore stored in one place. The bank then decided to retire the mainframe computer and replace it with a distributed system. Each branch office now has a master computer that stores local accounts and handles local transactions. In addition, each computer is connected with all the other branch computers via a global area network. If transactions can be performed without regard to where the customer actually is or where the customer's account data is actually stored, and if the users cannot tell the difference between the new system and the centralized mainframe-based system it replaced, this is a successful distributed system.
What would cause the bank to replace the centralized system with a distributed system? Cost is the chief factor driving the industrywide push toward distributed systems. It can be much more economical to purchase and administer hundreds or even thousands of PCs than to purchase and maintain a single mainframe computer. But price alone is not the reason. A well-designed distributed system yields better performance for the same amount of money.
Another factor that might influence the bank's decision is that a distributed system can outperform any mainframe. Current technology makes it possible to build a network of 5,000 Intel Pentium-based PCs, each running at about 200 million instructions per second (MIPS), yielding a total performance of 1 million MIPS. A single CPU producing that kind of performance would need to execute one instruction every 10-12 seconds. Even assuming that electricity could travel at the speed of light (300,000 kilometers per second), only a distance of 0.3 millimeter would be covered in 10-12 seconds. To build a CPU with that sort of performance in a 0.3-millimeter cube would truly be a feat of modern engineering. (The CPU would generate so much heat that it would spontaneously combust.)
Reliability is both a major concern and a goal of any distributed system. A well-designed distributed system can realize much higher overall reliability than a comparable centralized system. For example, if we conclude that a particular centralized system has a failure rate of only 2 percent, we can expect users to experience 2 percent system downtime. During that downtime, all work grinds to a halt. In a distributed system, we might evaluate each node as having a 5 percent failure rate. (The difference in failure rates can be attributed to the fact that most mainframe computers are kept in specially cooled and dust-free rooms with an around-the-clock team of trained operators, while PCs are often locked in a closet and forgotten.) Ideally, fewer than 5 percent of the machines are down at any one moment, which translates into only a 5 percent degradation of total system performance—not total system failure. For mission-critical applications, such as control of nuclear reactors or spaceship navigation systems, in which reliability and redundancy are of paramount importance, a distributed system introduces an extra degree of reliability.
In the following formula, P is the probability of occurrence of the two unrelated events A and B:
![]()
The more general case is shown here:
Pc,n = cn × 10-2n
Pc,n is the probability that if there are n unrelated events and each one has a c percent probability of failure, all events will fail simultaneously. Thus, even with a 5 percent rate of failure per node, users of a system with 100 nodes will experience only a 20-100 percent chance of any downtime whatsoever. (This case is rather extreme since it is highly unlikely that 100 out of 100 computers would fail simultaneously.) Let's use the logic shown above to evaluate the risk of several computers failing at the same time.
Figure 1-1 shows the likelihood of simultaneous failure for between 1 and 5 computers out of a total of 10.
Distributed systems do not need to be taken off line for upgrade or maintenance work. Several servers can be taken off line at one time or additional servers can be added, all without unduly inconveniencing users or jeopardizing the company's main business. Capacity planning can also be done in a more sane and logical manner because there is little incentive to purchase extra processing power in advance of need.
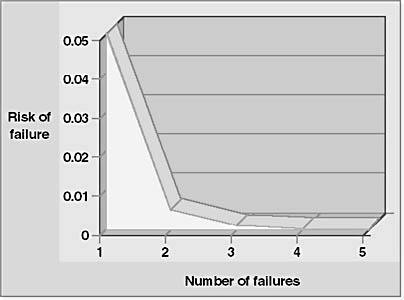
Figure 1-1. Risk of multiple simultaneous failures in a system of 10 nodes.
In recent years, there has been much talk about migrating enterprise-wide systems from the two-tier paradigm called the client/server model to a three-tier architecture. The surging popularity of the Internet, the advent of the Java programming language, and the advent of the network computer have all spurred interest in the concept of three-tier system architecture. Later in this chapter, we'll take a look at the three-tier solution and examine how COM+ fits in with this architecture.